编译过程
本文共 593 字,大约阅读时间需要 1 分钟。
由程序生成可执行文件经过了预编译——编译——汇编——链接的过程。其中编译的步骤分为:词法分析、语法分析、语义分析、中间语言生成、目标代码生成及优化(如下图)。
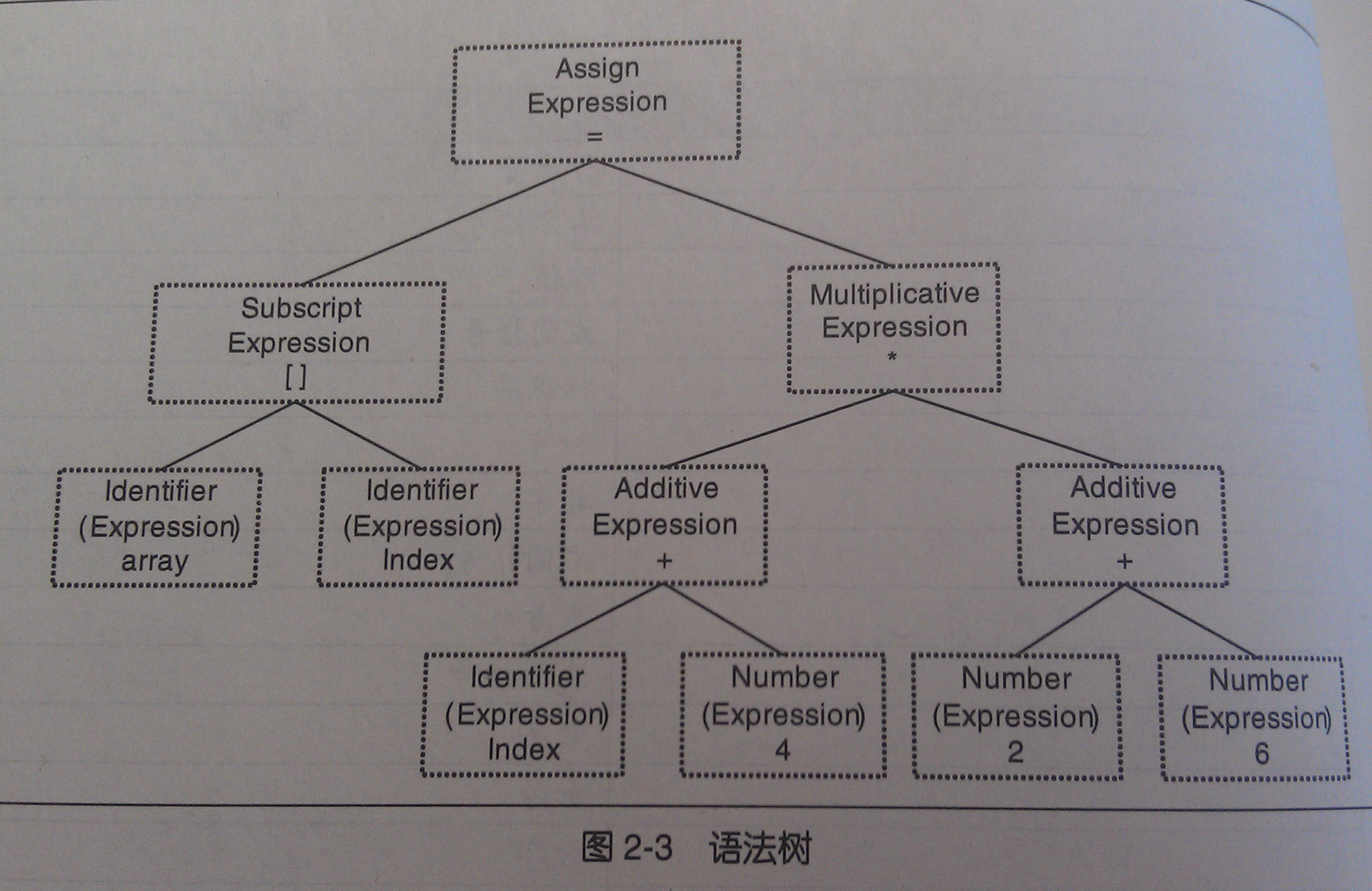
例子:array[index] = (index + 4) * (2 +6)
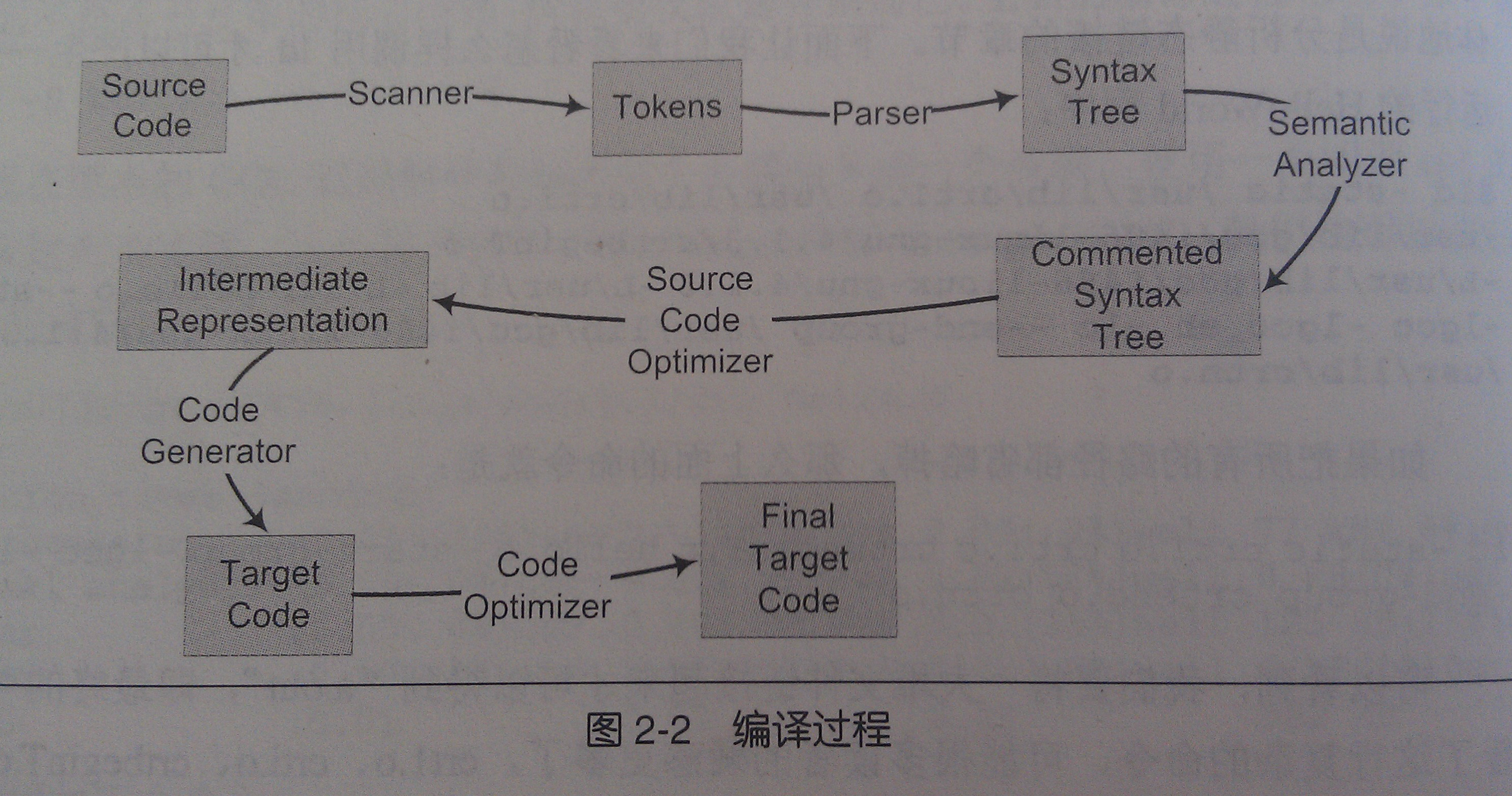
首先是词法分析形成一个个的记号,之后进行语法分析产生语法树。
接下来进行语义分析,编译器所能分析的语义是静态语义,所谓静态语义是指在编译期可以确定的语义,与之对应的动态语义就是只有在运行期才能确定的语义。
静态语义通常包括声明和类型的匹配,类型的转换。动态语义一般指在运行期出现的语义相关的问题(比如多态)。

之后进行中间代码的优化,由于在语法树上做优化比较困难,所以源代码优化器往往将整个语法树转换成中间代码,它是语法树的顺序表示,其实已经很接近目标代码了。但是它一般跟目标机器和运行时环境是无关的,比如它不包含数据的尺寸、变量地址和寄存器的名字等。(其实就是语法树的一种表示)比较常见的就是三地址码和P-代码。
中间代码使得编译器可以被分为前端和后段。编译器前端负责产生机器无关的中间代码,编译器后端将中间代码转换成目标机器代码。这样对于一些可跨平台的编译器而言,它们可以针对不同的平台使用同一个前端和针对不同极其平台的数个后端。
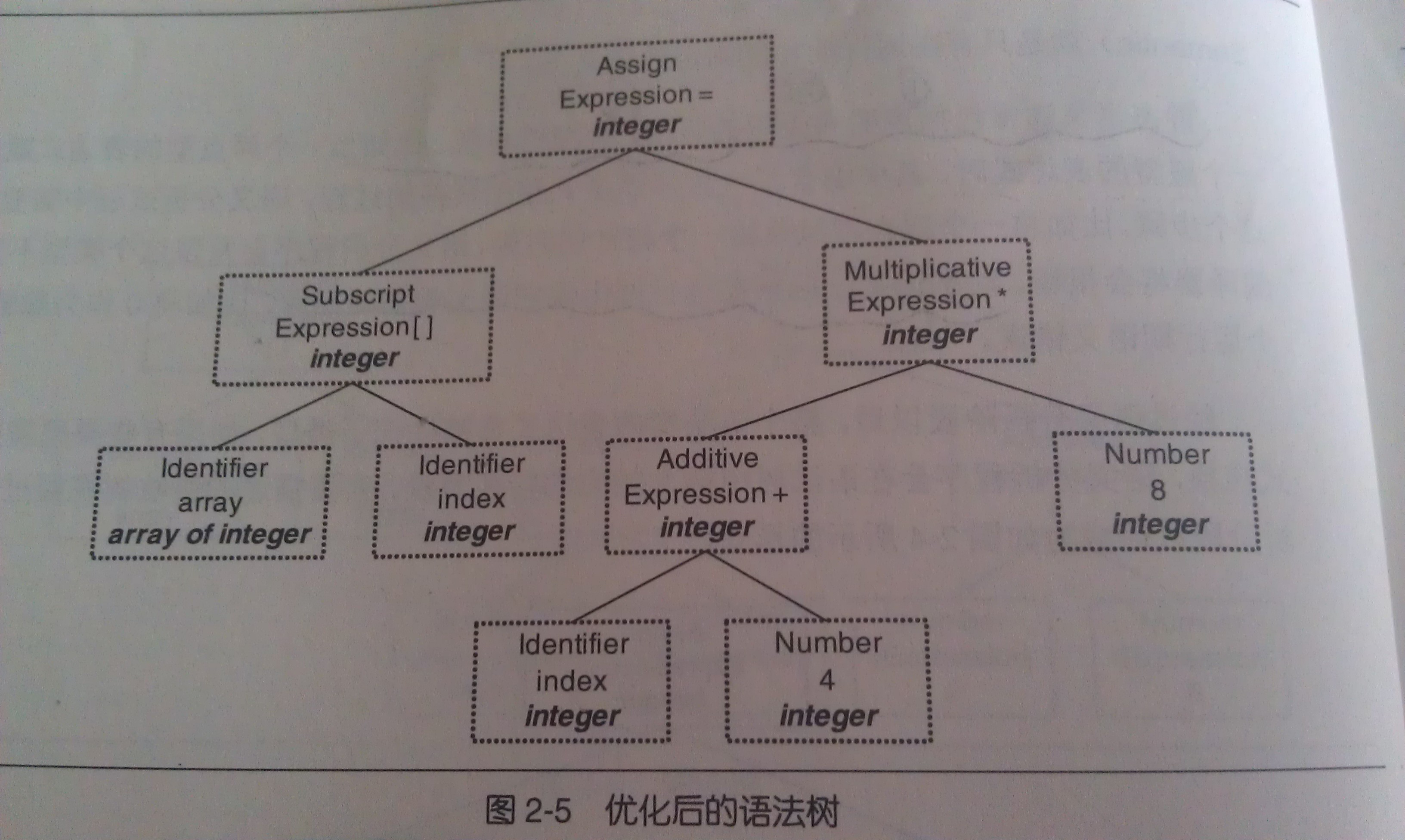
最后将进行目标代码的生成与优化。目标代码的优化包括选择合适的寻址方式、使用唯一来代替乘除运算、删除多余的指令等。
你可能感兴趣的文章
在 XML 中有 5 个预定义的实体引用
查看>>
XML 元素是可扩展的
查看>>
避免 XML 属性?针对元数据的 XML 属性
查看>>
XML DOM nodeType 属性值代表的意思
查看>>
JSP相关知识
查看>>
JDBC的基本知识
查看>>
《Head first设计模式》学习笔记 - 适配器模式
查看>>
《Head first设计模式》学习笔记 - 单件模式
查看>>
《Head first设计模式》学习笔记 - 工厂方法模式
查看>>
《Head first设计模式》学习笔记 - 装饰者模式
查看>>
《Head first设计模式》学习笔记 - 模板方法模式
查看>>
《Head first设计模式》学习笔记 - 外观模式
查看>>
《Head first设计模式》学习笔记 - 命令模式
查看>>
《Head first设计模式》学习笔记 - 抽象工厂模式
查看>>
《Head first设计模式》学习笔记 - 观察者模式
查看>>
《Head first设计模式》学习笔记 - 策略模式
查看>>
ThreadLocal 那点事儿
查看>>
ThreadLocal 那点事儿(续集)
查看>>
阳台做成榻榻米 阳台做成书房
查看>>
深入分析java线程池的实现原理
查看>>